AV-Reasoner: Improving and Benchmarking Clue-Grounded Audio-Visual Counting for MLLMs

Abstract
Despite progress in video understanding, current MLLMs struggle with counting tasks. Existing benchmarks are limited by short videos, close-set queries, lack of clue annotations, and weak multimodal coverage. In this paper, we introduce CG-AV-Counting, a manually-annotated clue-grounded counting benchmark with 1,027 multimodal questions and 5,845 annotated clues over 497 long videos. It supports both black-box and white-box evaluation, serving as a comprehensive testbed for both end-to-end and reasoning-based counting. To explore ways to improve model's counting capability, we propose AV-Reasoner, a model trained with GRPO and curriculum learning to generalize counting ability from related tasks. AV-Reasoner achieves state-of-the-art results across multiple benchmarks, demonstrating the effectiveness of reinforcement learning. However, experiments show that on out-of-domain benchmarks, reasoning in the language space fails to bring performance gains.
Benchmark
LeaderBoard
Statistics
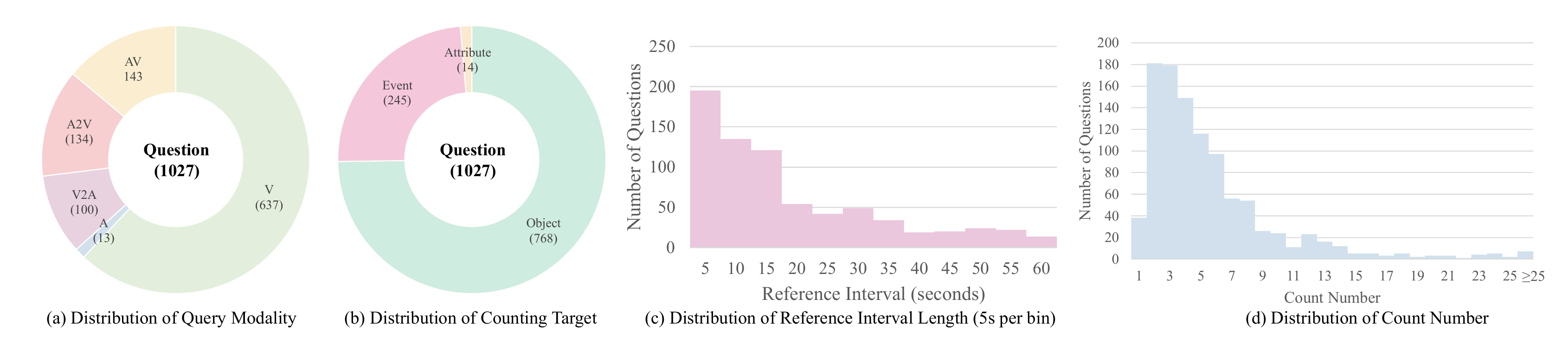
CG-AV-Counting is based on a subset of 497 videos from CG-Bench. The benchmark includes 1,027 multimodal-query questions and 5,845 fine-grained manually-annotated clue annotations. Nearly 40% of the samples require the model to use both audio and visual modalities for counting, while others only require the visual modality. This design ensures that the benchmark is applicable to both visual models and audio-visual models. The benchmark includes object, event, and attribute counting target. Among them, attribute counting is more challenging because it requires grouping objects with the same attribute based on the query.
This benchmark spans a numerical range from 1 to 76, with a long-tail distribution, where most counts fall between 1 and 20. Video content includes over 10 categories, such as sports, life record, humor, tutorials, etc., offering greater domain diversity than existing benchmarks. All videos in the benchmark exceed 10 minutes, and reference intervals range from seconds to minutes, covering both short-term and long-range dependencies.
Comparison

To the best of our knowledge, there is currently no comprehensive benchmark specifically designed to evaluate MLLMs' video counting capabilities. DVD-Counting and VideoNIAH use synthetic data for object counting. They have limited counting target variety and do not have long videos. Other benchmarks, such as MVBench and WorldSense, include real-world videos, but counting is only a subtask of the overall evaluation, resulting in a smaller number of samples. Datasets for repetitive action counting feature short videos and simple queries, making them unsuitable for evaluating MLLMs. Besides, most benchmarks only have visual queries, which limits their ability to fully evaluate Omni-MLLMs.
Unlike previous counting benchmarks, our benchmark incorporates both audio and visual modalities, features more complex queries, and provides fine-grained counting clues to jointly evaluate models' abilities in both end-to-end and reasoning-based counting.
Evaluation Metrics
We follow CG-Bench's dual evaluation protocol to assess MLLMs' counting ability:
Black-box Evaluation
Assesses end-to-end counting under two settings:
- Long Acc: Model counts and temporally localizes in the full video.
- Ref Acc: Model counts in a trimmed reference segment, isolating counting from localization.
Counting measured by four metrics:
- Accuracy (Acc): Exact count prediction rate.
- Off-By-One Accuracy (OBOA): Correct if off by ≤1.
- Mean Absolute Error (MAE): Average counting error magnitude.
- Root Mean Square Error (RMSE): Penalizes larger errors more.
White-box Evaluation
Assesses localization with explicit evidence:
- Event counting: Temporal Intersection over Union (tIoU) of predicted segments.
- Object counting: Spatial IoU of predicted bounding boxes for first object appearances.
- Attribute counting: Clustered bounding boxes compared by IoU.
White-box Counting Score (WCS): Combines localization accuracy and counting penalty:
Score ranges 0–100; 100 means perfect count and localization, 0 means large count mismatch or format error.
Instruction-Following Accuracy (IFA): Proportion of outputs matching required format, ensuring reliability and interpretability.
Baseline: AV-Reasoner
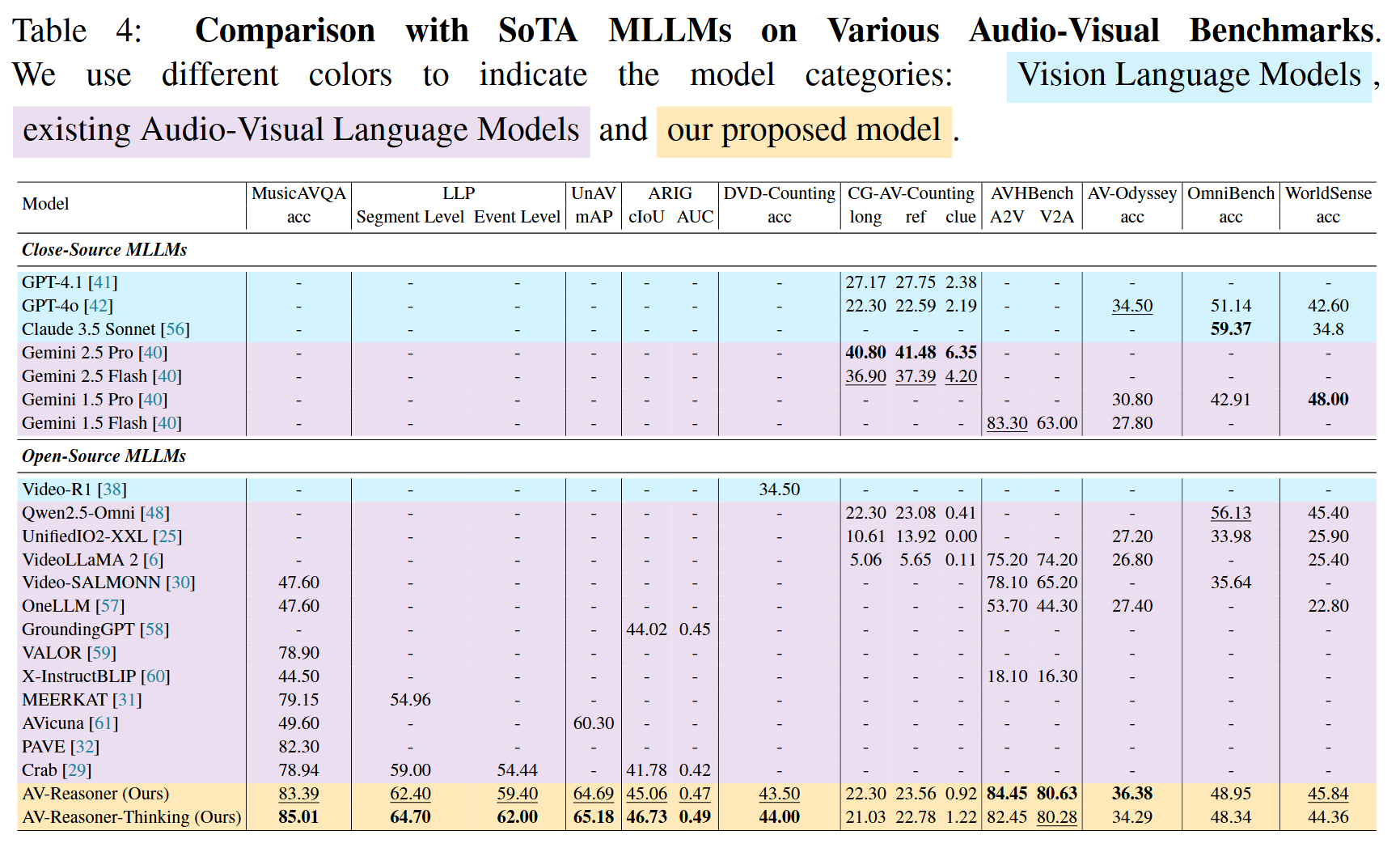
Comparison with State-of-the-Art MLLMs
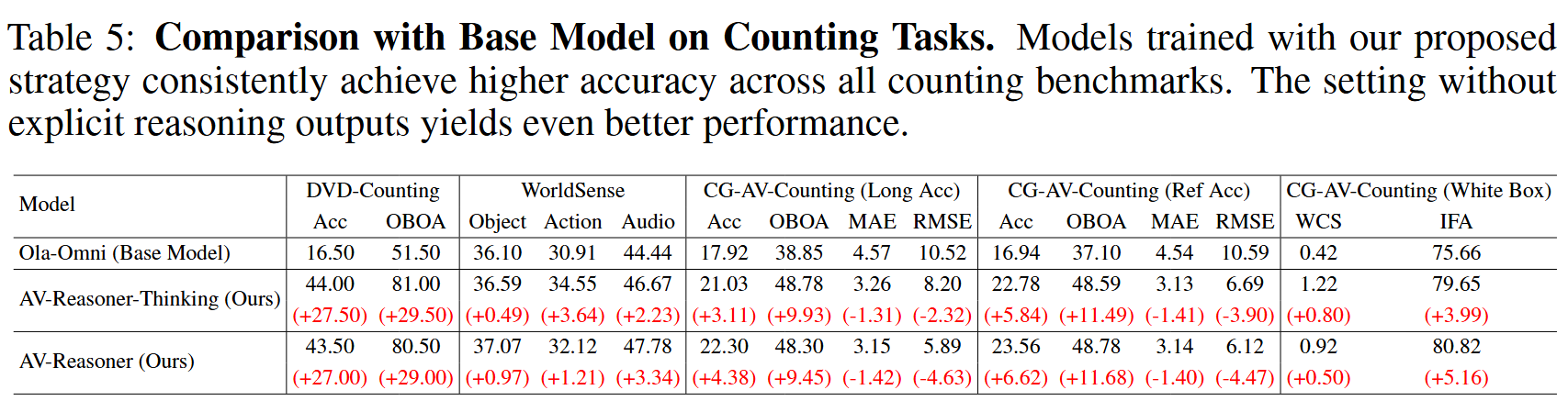
Comparison with Base Model on Counting Tasks
Examples
A. Car horn B. Civil defense alarm C. small bell D. Chimes

The video shows a civil defense siren, which is a type of alarm used for emergencies. The siren is clearly visible and is the main source of sound in the video. The other options, such as car horn, small bell, and chimes, are not present in the video. Therefore, the main sound source is the civil defense siren.B

Citation
@misc{lu2025avreasoner,
title={AV-Reasoner: Improving and Benchmarking Clue-Grounded Audio-Visual Counting for MLLMs},
author={Lidong Lu and Guo Chen and Zhiqi Li and Yicheng Liu and Tong Lu},
year={2025},
eprint={2506.05328},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05328},
}
@misc{chen2024cgbench,
title={CG-Bench: Clue-grounded Question Answering Benchmark for Long Video Understanding},
author={Guo Chen and Yicheng Liu and Yifei Huang and Yuping He and Baoqi Pei and Jilan Xu and Yali Wang and Tong Lu and Limin Wang},
year={2024},
eprint={2412.12075},
archivePrefix={arXiv},
primaryClass={cs.CV}
}

powered by Academic Project Page Template